
Hi, I'm Can Gokmen.
I'm a senior at Boston University in the BA/MS program — BA in Math & Computer Science, MS in Computer Science, with a Physics minor. Trustee Scholar. I do research on data-intensive systems and efficient ML inference, and I build software in between.
- May 2026 — PresentVisiting Undergraduate Research AssistantHarvard University — Data & AI Systems Lab
Ongoing work (in progress) with Dr. Utku Sirin (Research Associate) and Prof. Stratos Idreos on incremental image serving for efficient vision inference. The system targets VLM and VFM workloads such as visual question answering, zero-shot image classification, zero-shot object presence detection, segmentation, and image-to-image retrieval.
Building a serving engine that streams each image progressively as DCT frequency bands and escalates model size only when accuracy demands it. At every step a cost model weighs the cost of sending more frequency bands against the cost of moving to a larger model, accounting for disk read and decompression, PCIe transfer, image reconstruction, GPU-to-GPU communication, and GPU compute, then picks the cheaper option.
Early results show the frequency cascade reaching full-image accuracy while transmitting up to 5x less data per sample, and the model cascade hitting target accuracy at lower p95 latency than always serving the largest model. The project is still actively under development.
- Sep 2024 — PresentUndergraduate Research AssistantBoston University — Data-intensive Systems & Computing Lab
Working with Prof. Manos Athanassoulis and Aneesh Raman (now at Salesforce) in the Data-intensive Systems and Computing (DiSC) Lab.
Proposed QuART (Quick Insertion Adaptive Radix Tree), integrating sortedness-aware concepts into ART. Designed a new fast-path insertion algorithm that cut insertion time by 86% on fully sorted datasets (47% on average). Extended the fast path to multiple streams, reaching up to 3x speedups.
Brought QuART into production systems. Replaced the ART used in PostgreSQL's VACUUM (the TidStore dead-tuple path) with QuART, cutting end-to-end vacuum time by up to 18% on a billion-row table, and ported the stail design to Redis' rax, the compressed radix tree behind Streams, lifting ingestion throughput by about 20% on average.
Contributed to the early phases of the VLDB 2026 demo project, 'Demonstrating Indexing for Near-Sorted Data'.
- May 2024 — Aug 2024Software Engineer InternBoyner
Worked on the architecture team, focused on the structural health of the .NET codebase and the platform's path to .NET 8. Cut PhotoUtility memory by 35% and CPU by 30%. Wired NetArchTest into CI to enforce the onion architecture across services, codifying the layering rules so dependency-direction violations were caught at build time and preventing roughly 70% of them. Audited the codebase for breaking changes and flagged 7 high-risk projects ahead of the .NET 8 migration.
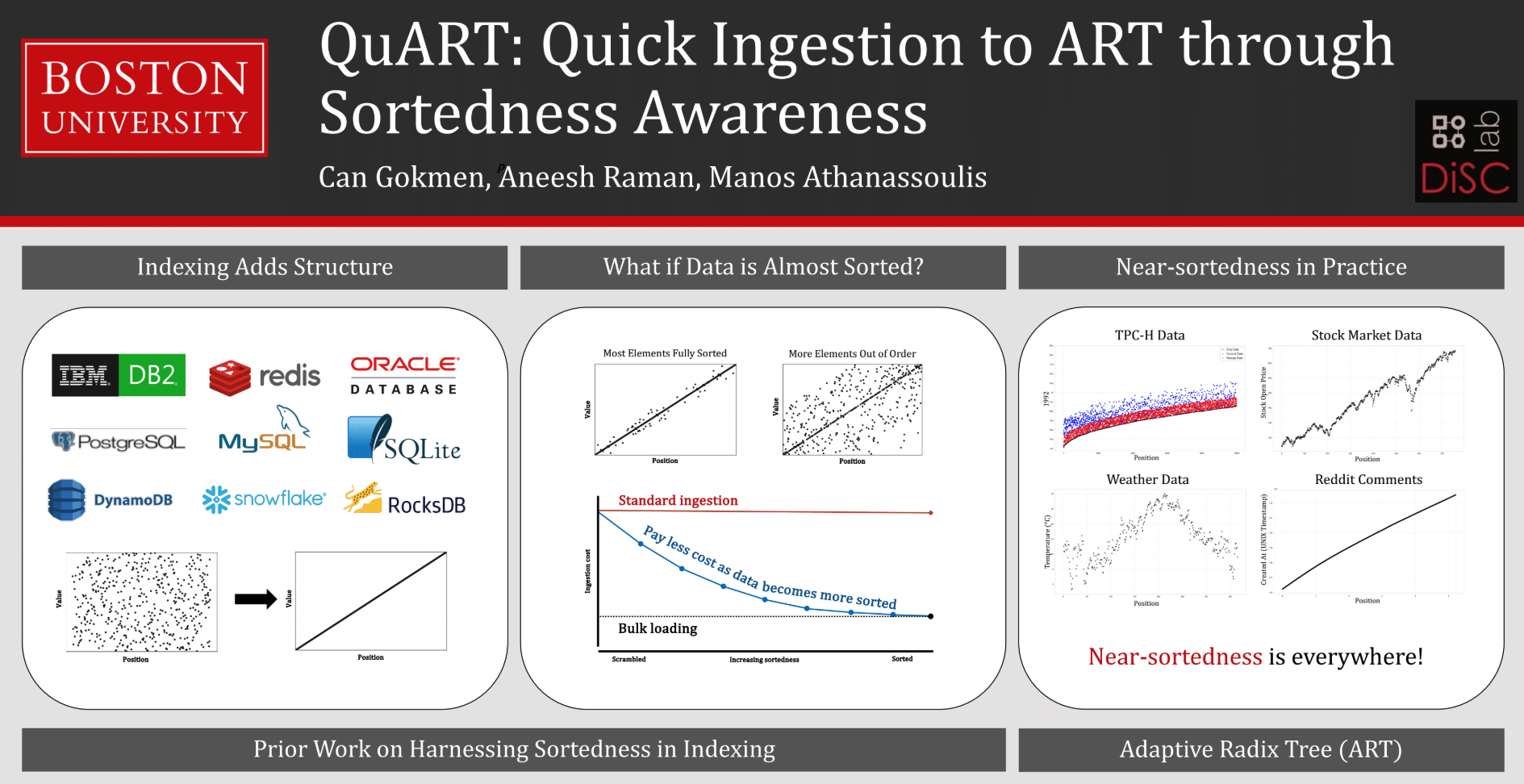
QuART — Quick Ingestion to ART
A sortedness-aware Adaptive Radix Tree that skips redundant root-to-leaf traversal by reusing cached insertion state along shared prefix paths. Improves ART insertion throughput by up to 1.4x on near-sorted streams and over 10x with bulk loading. Ported into production, it speeds up PostgreSQL's VACUUM by up to 18% and Redis Streams ingestion by about 20% on average.

Andromeda
An AI-powered Android wellness tracker with a Wear OS companion for logging weight, diet, sleep, water, and activity. Built with Kotlin and Jetpack Compose, it keeps data on-device and uses Gemini on Vertex AI for proactive tips and a voice-enabled chatbot, with bidirectional phone-to-watch sync.
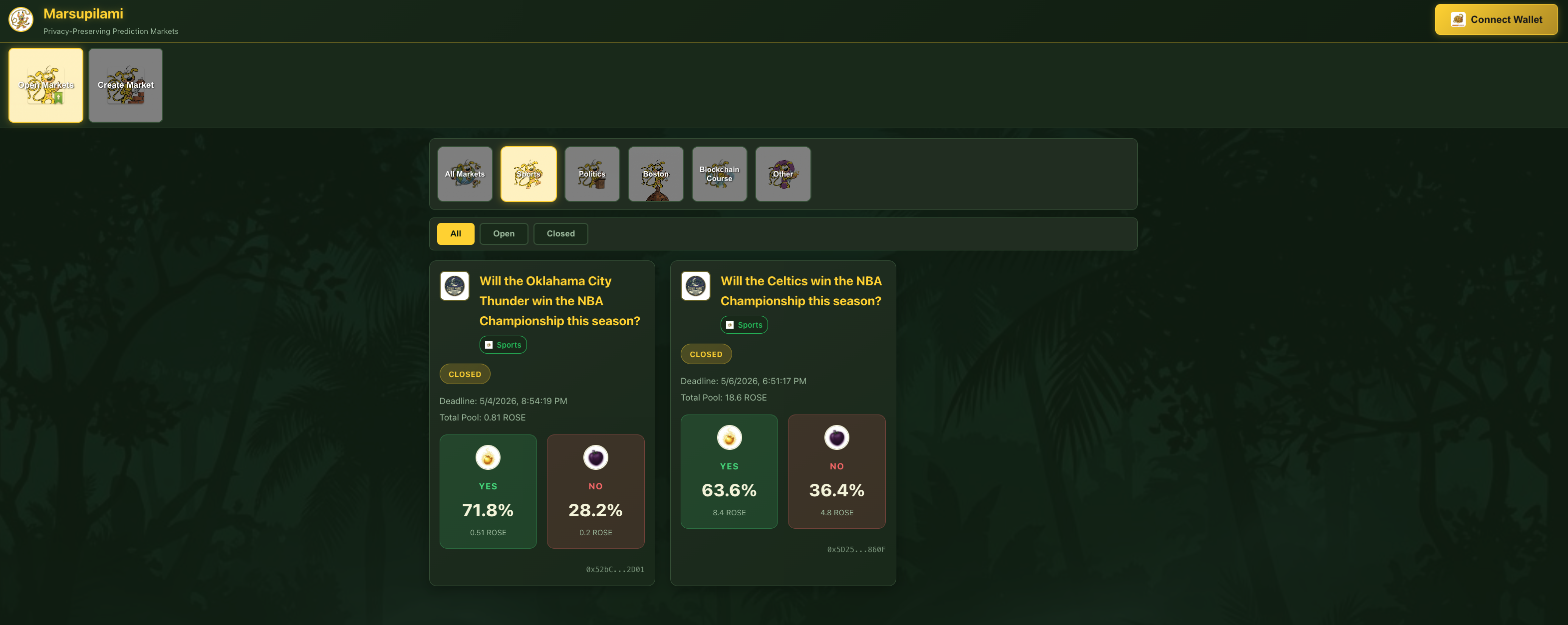
Marsupilami
A privacy-preserving prediction market built on the Oasis Sapphire confidential EVM, where each YES/NO bet stays encrypted and never appears on-chain. Solidity contracts with a React frontend, using TEEs and periodic aggregated odds disclosure to block correlation attacks, plus stake-based oracle resolution.
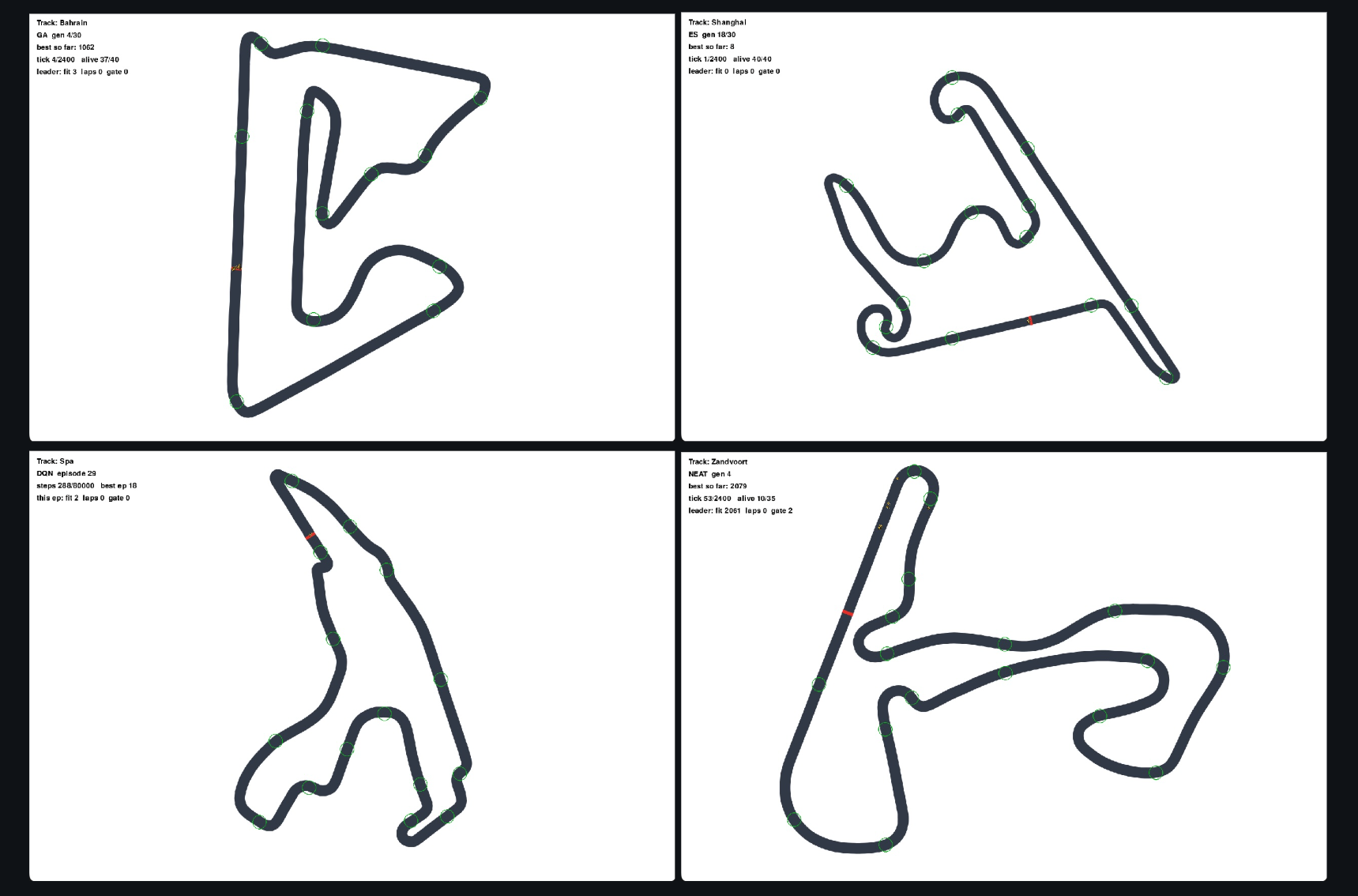
Self-Driving F1
A self-driving car simulation that evolves neural networks to drive eight real F1 tracks using NEAT, built in Python with pygame. It extends into a cross-paradigm benchmark pitting NEAT against a fixed-MLP genetic algorithm, OpenAI-ES, and DQN on the same step budget, where NEAT's growing topology wins on a 300k-step Silverstone run.
RSVD for Low-Rank Attention
A study of randomized SVD as a drop-in replacement for classical SVD in the low-rank compression of transformer attention. Across synthetic benchmarks rSVD delivers sizable speedups at a small reconstruction-error cost, and in the SVD-LLM pipeline it cuts total compression time by around 1.5x with nearly unchanged perplexity and throughput.
The fastest way to reach me is email. I'm happy to talk about SWE roles, research collaborations, or anything in the systems/ML space.